crawlergo-to-xray(server酱推送微信)
环境准备
debian系liunx(kali)
python3.8(3.7以上)
配置server
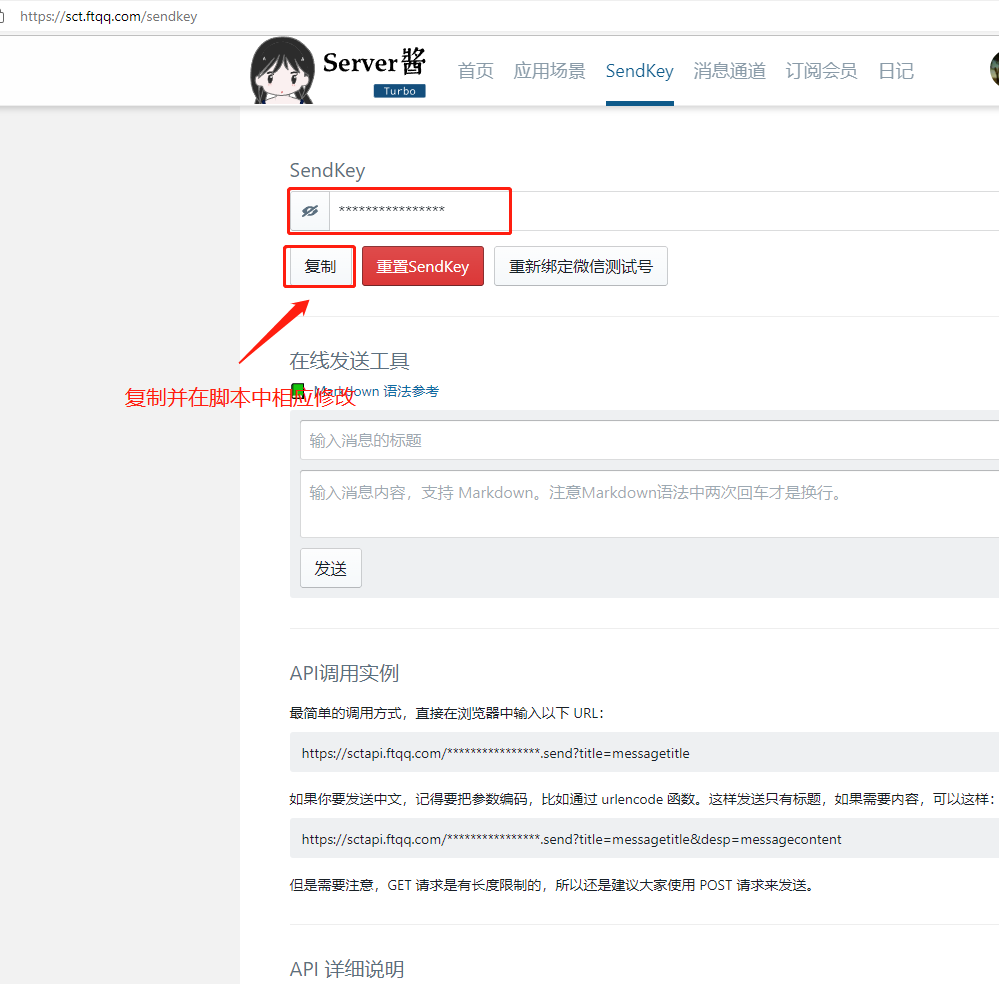
扫码关注同时即可完成绑定
https://sct.ftqq.com/
给webhook.py配置api
替换相应的参数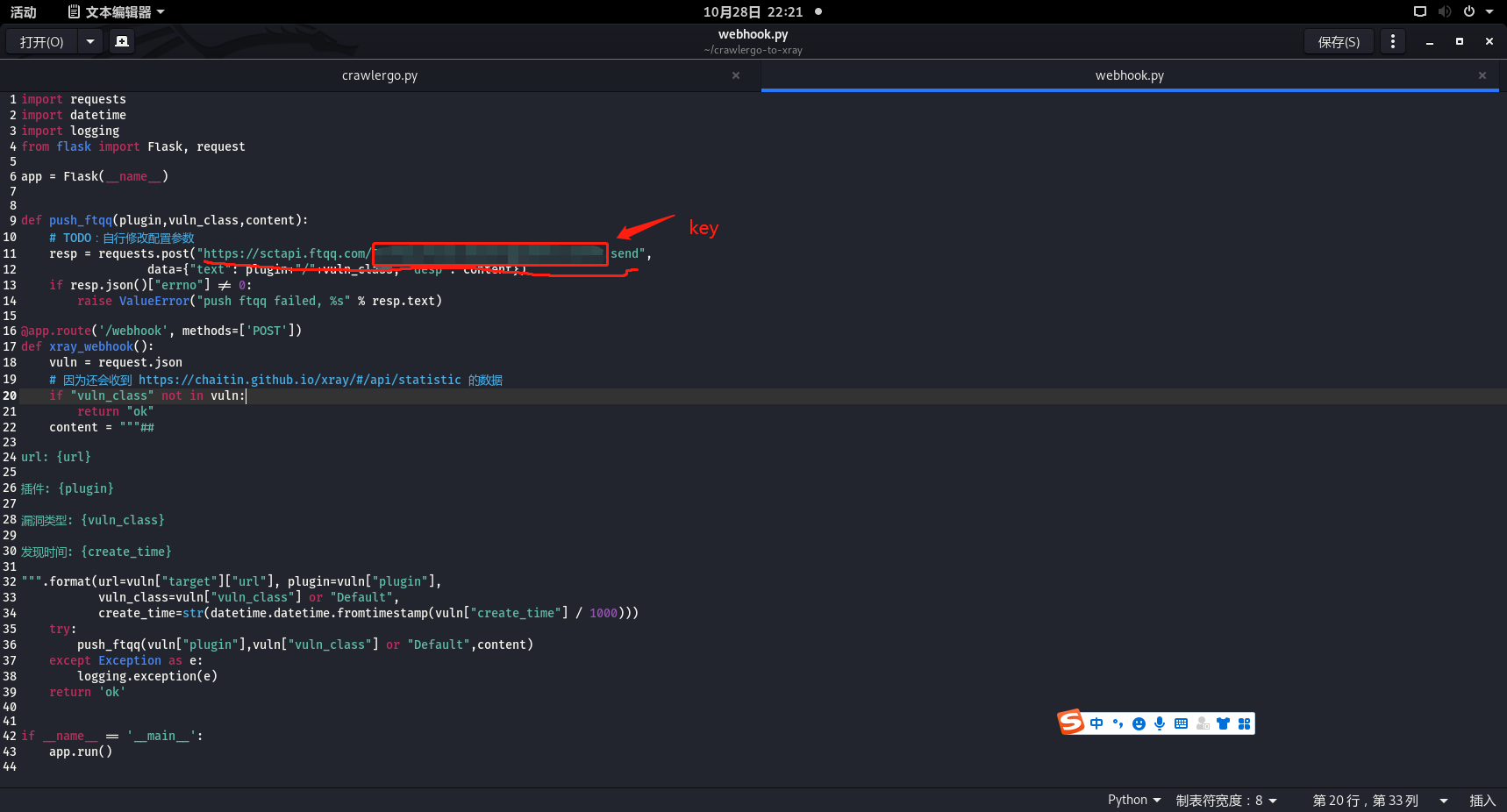
运行
python3 webhook.py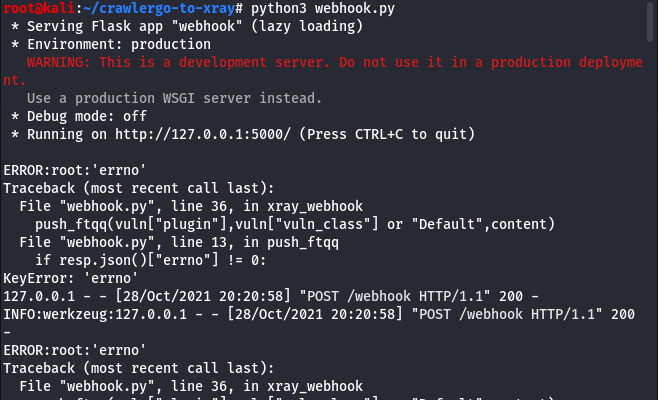
配置xray
- 初始配置,生成证书,配置config,给权限
chmod +x xray_linux_amd64 |
配置config.yaml
这里主要配置认证登录的username以及password和cookie值,针对登录系统爬虫。
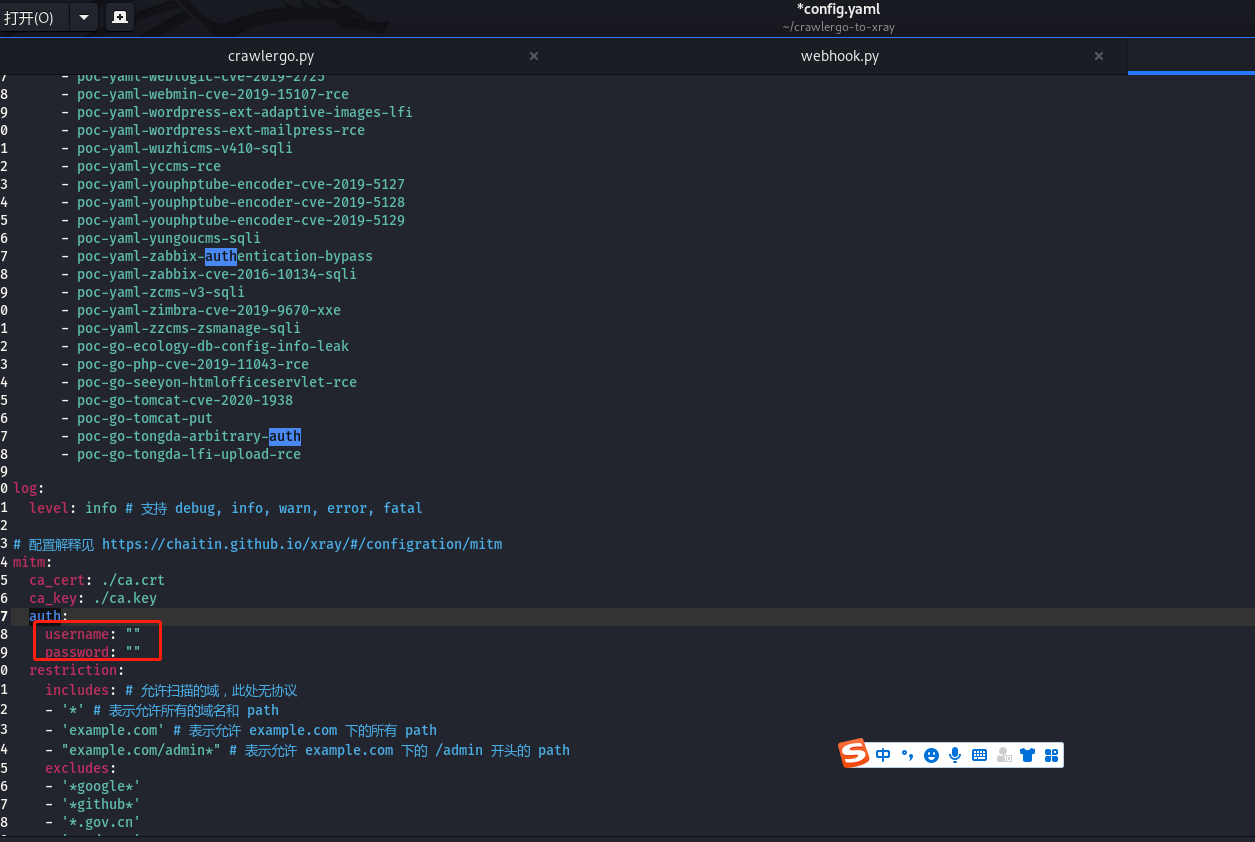
设置自己浏览器中ua头

- 启动xray并查看日志(需要自行修改xray的配置文件以及命令行中的的配置,建议在xray里面配置username和password,以及[xray_port和webhook_port端口)
./xray_linux_amd64 webscan --listen 127.0.0.1:7777 --webhook-output http://127.0.0.1:5000/webhook --html-output xray.html
kali安装chrome
- 下载安装包
root@kali:~# wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
- 安装(如果提示报错,执行第三步处理依赖关系。)
root@kali:~# dpkg -i google-chrome-stable_current_amd64.deb
- 解决依赖关系
root@kali:~# apt-get -f install
- 安装依赖包
root@kali:~# apt-get install google-chrome-stable
- 查看目录
which google-chrome-stable
可参考网上其它安装方法
配置crawlergo
- 修改chorme的路径地址以及代理IP地址
如果需要更准确的爬虫,需要设置cookie和user-agent信息以及加上代理的ip和用户名和密码,cookieh和user-agent值可以通过登录系统后,xyay的代理IP和用户名和密码,可以根据前面设置的xray的配置获得。
抓包获取
./crawlergo", "-c", "/usr/bin/google-chrome","-t", "10","-f","smart","--fuzz-path", "--output-mode", "json","--ignore-url-keywords", "quit,exit,logout", "--custom-headers", simplejson.dumps(headers),"--robots-path","--log-level","debug","--push-to-proxy","http://xray_username:xray_password@xray_ip:xray_port",target |
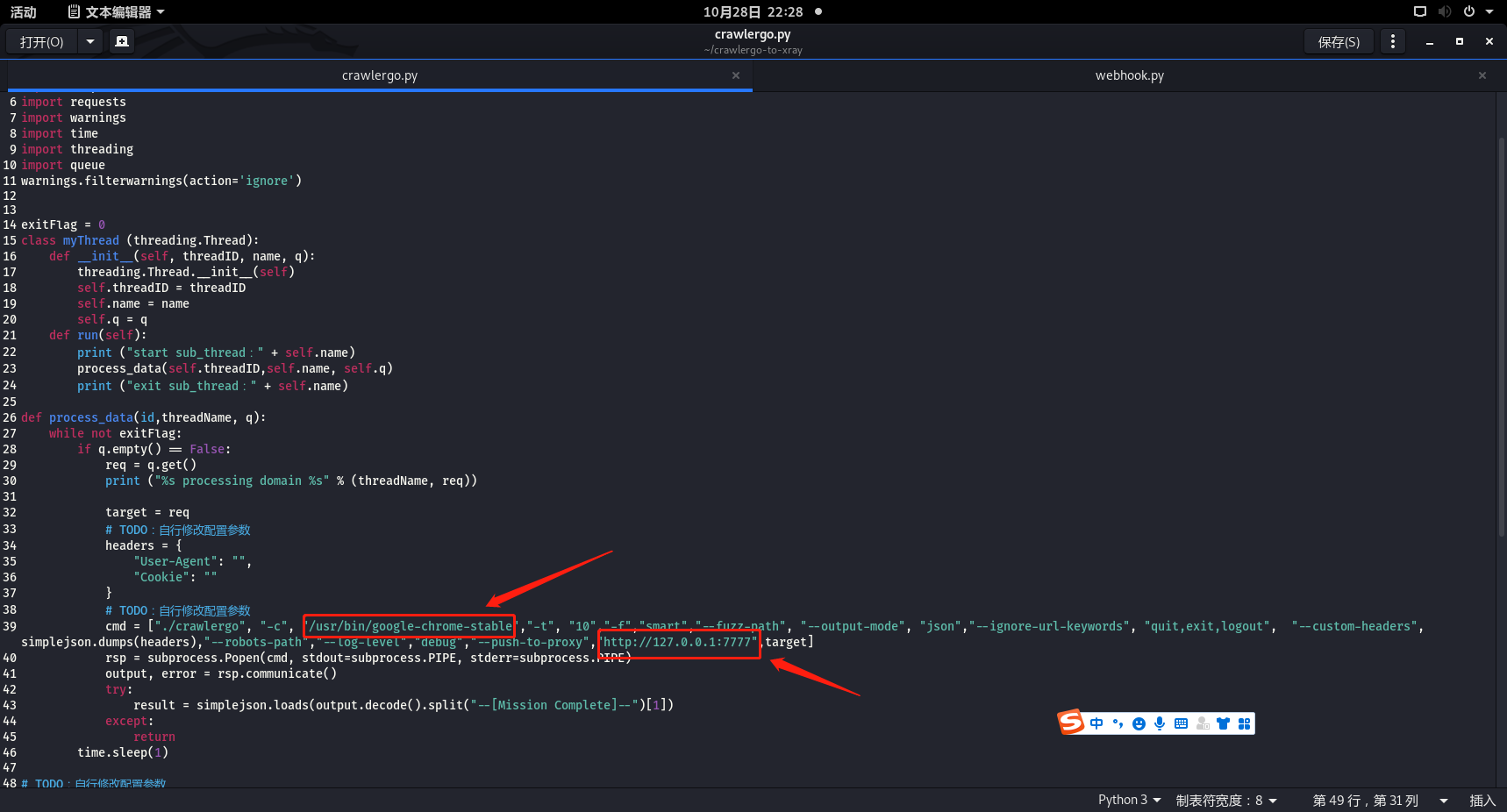
- 运行
chmod +x crawlergo
写入自己要扫的域名vi targets.txt
运行python3 crawlergo.py
微信端查看到漏洞情况
免费用户每天只有五次免费
可以用nohup命令后台运行并日志保存
nohup python3 webhook.py > webhook.log 2>&1 &
nohup python3 crawlergo.py > crawlergo.log 2>&1 &
nohup ./xray_linux_amd64 webscan –listen 127.0.0.1:7777 –webhook-output http://127.0.0.1:5000/webhook –html-output xray.html > xray.log 2>&1 &
参考:
https://www.cnblogs.com/backlion/p/14288456.html
https://gitee.com/ty001007/crawlergo-to-xray/b2d46c43ae85405abaedad17deae0748.png)



